
Web上にある膨大な情報を有効に活用して戦略に活かす、これもDXの一つでしょう。戦略づくりにはマクロな視点が求められますが、Webでヒットした一つ一つの情報を羅列しても、なかなか経営層の理解を得ることは難しいと思います。
そこで、あるテーマに関する数百から数千件の情報を塊として取得して、それを可視化することで、全体の流れや動向を示したい場合があります。Web情報を取得、可視化し、解釈する、この流れのうち、Web情報の取得について、今回もRPAを使った簡単な方法をご紹介します。

作業の準備
今回は米国の医学文献データベースPubMedの検索結果を取得していきます。RPAは、今回もPower Automateを使います。Power Automateについては、前回の記事もご参照下さい。PubMedの取得には、APIを使った方法も用意されているのですが、PubMed以外のデーターベースにも応用がきくよう、RPAを使ったやり方をご紹介します。
なお、今回の方法は、いわゆるクローラーや、スクレイピングといった手法になりますので、注意が必要です。データベースによっては、機械的な取得を禁止していたり、また著作権法に触れたりする可能性もあります。この点は重要なので、別の機会に記事にしたいと思います。
PubMedクローラーをつくる
さて、ワークフローの全体像です。たったの7行です。この例では、PubMedで検索結果を表示して、情報を抽出してCSV で保存する、という内容になっています。検索結果は1ページに10件表示され、それを10ページ分取得して、この作業を3回まわしています。つまり合計300件の文献情報を取得し、CSVで保存します。
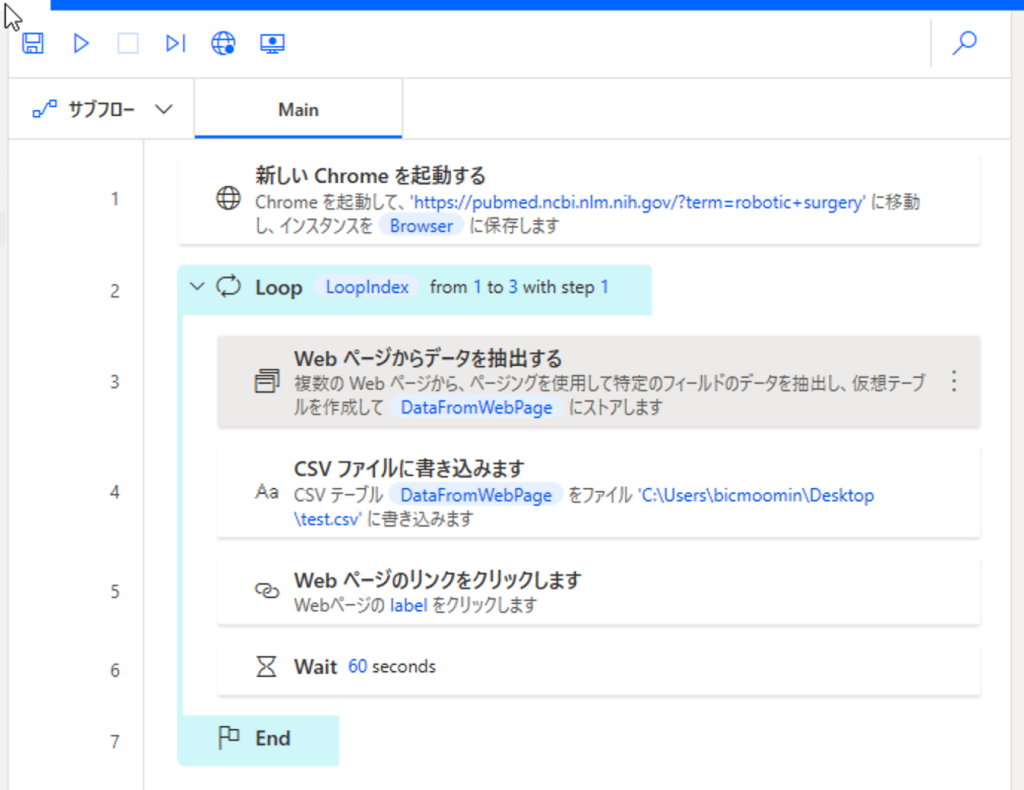
詳しく見てみましょう。1行目「新しいChromeを起動する」をつくってみます。Chromeブラウザを起動し、PubMedで何か検索結果を表示してみて下さい。その状態で、Power Automateで新しいフローを作成し、フロー入力画面上部中央のWebレコーダーをクリックします。
Chromeを選択して「次へ」、
Webレコーダー画面左上の「レコード」を押した状態で、ブラウザ画面のページ下のNextを押して、Webレコーダーを「一時停止」して下さい。「Webページの要素をクリック」が追加されていることを確認して、Webレコーダーを「終了」して下さい。
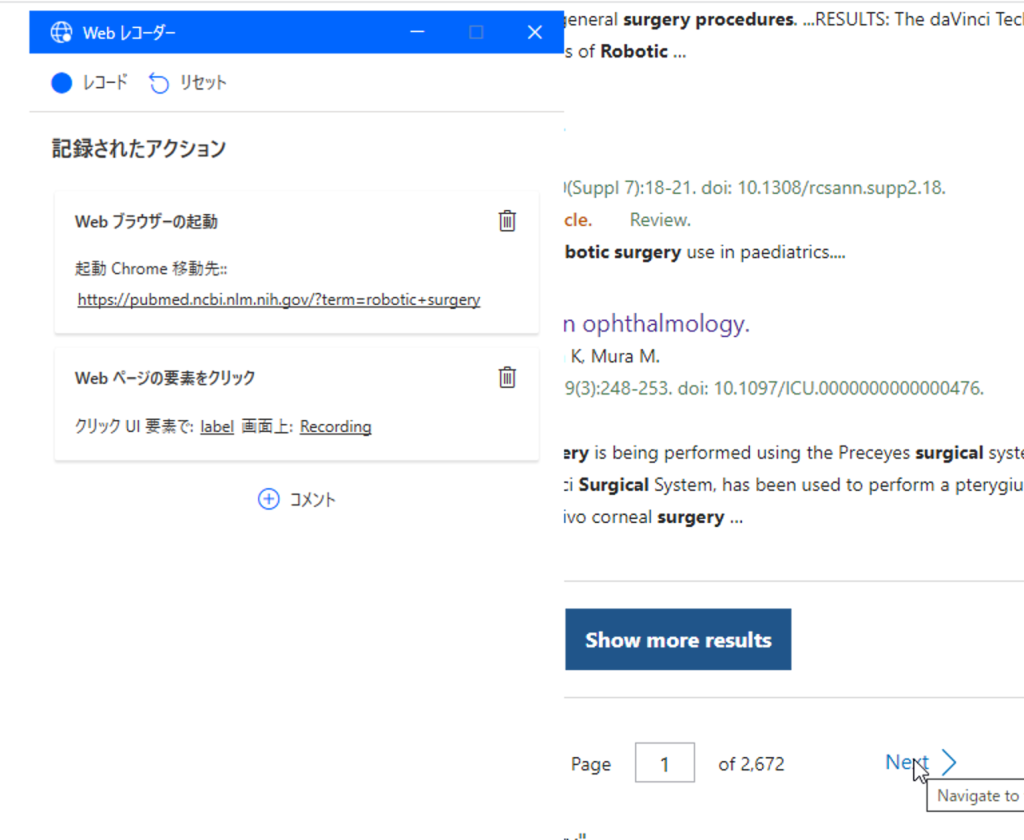
するとフローはこのようになっています。コメント行は削除して構いません。
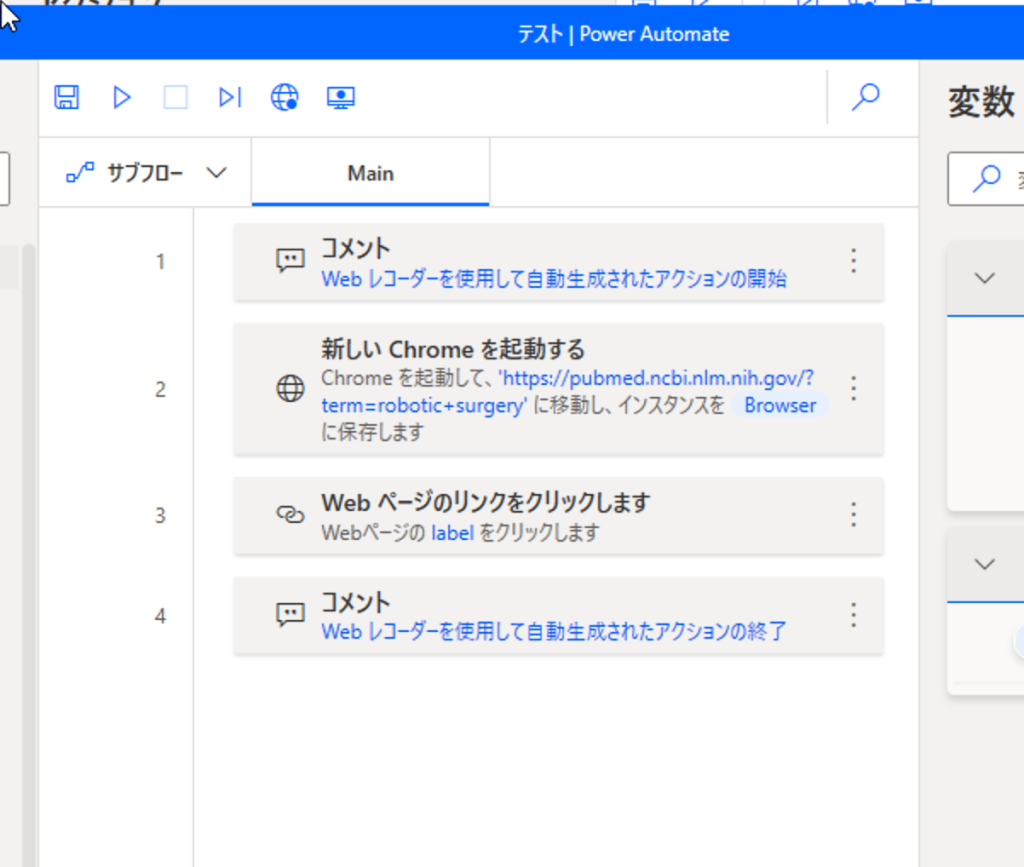
次に、アクション「Webページからデータを抽出する」を「新しいChromeを起動する」の下に追加します。その状態でブラウザへ行くと、ライブWebヘルパーというツールが開いているはずです。ブラウザにマウスオーバーすると、赤い枠が出てきます。
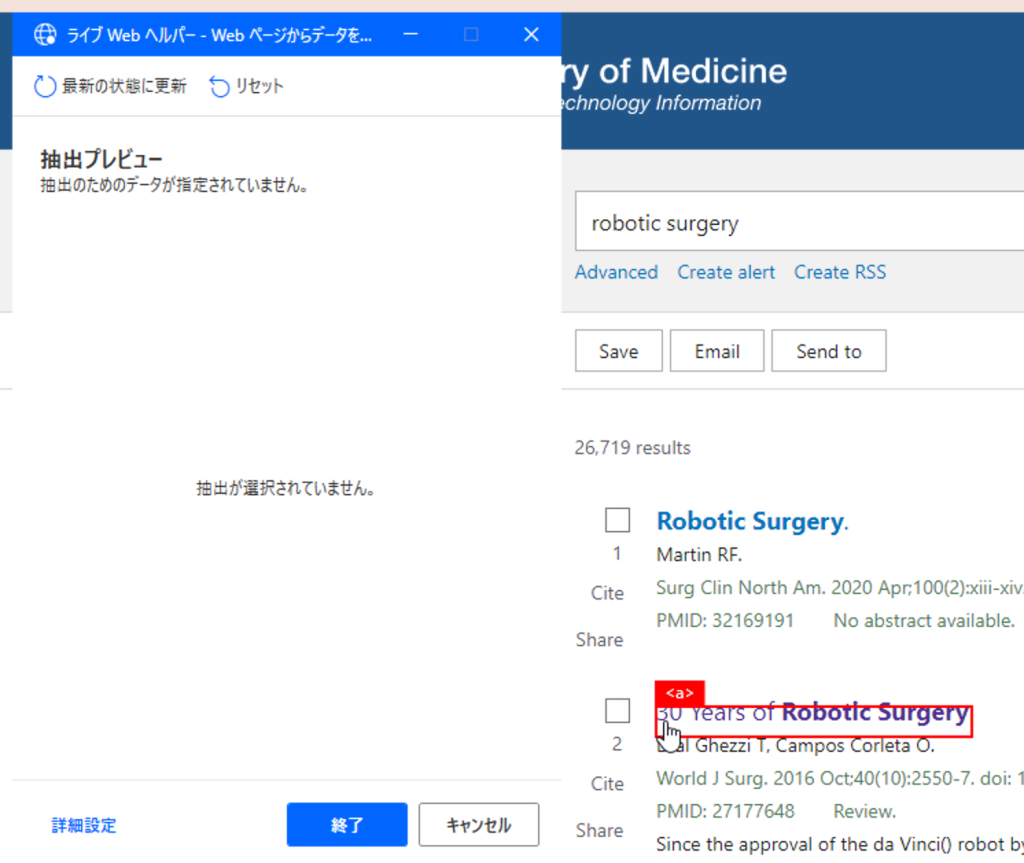
取得したい情報(例えばタイトル)を、赤枠に入れた状態で右クリックし、要素の値を抽出>テキスト:・・を選択すると、抽出プレビューにデータが入ります。
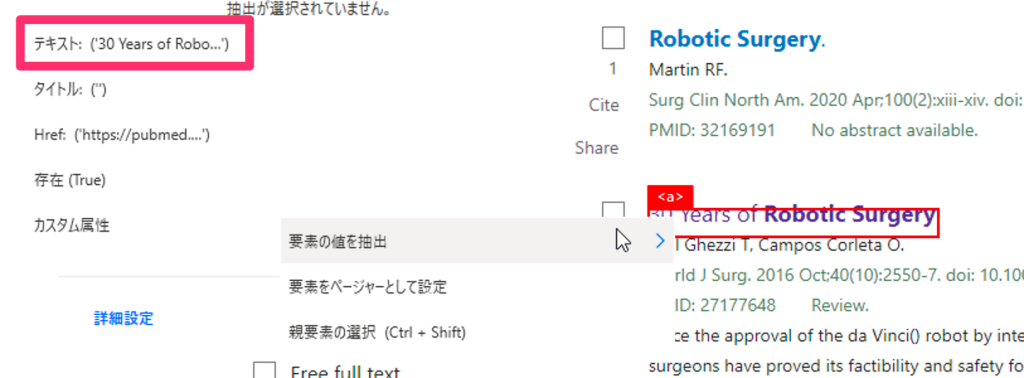
ここから1つ目のポイントですが、次に取得したい情報としてタイトル以外の項目(例えば要約)を選択しないで下さい。システムに、検索結果の構造を理解させるために、すぐ下の別のタイトル行をもう一度、赤枠から登録します。すると、ページ内10件のタイトルがプレビューに表示され、システムが構造を理解します。
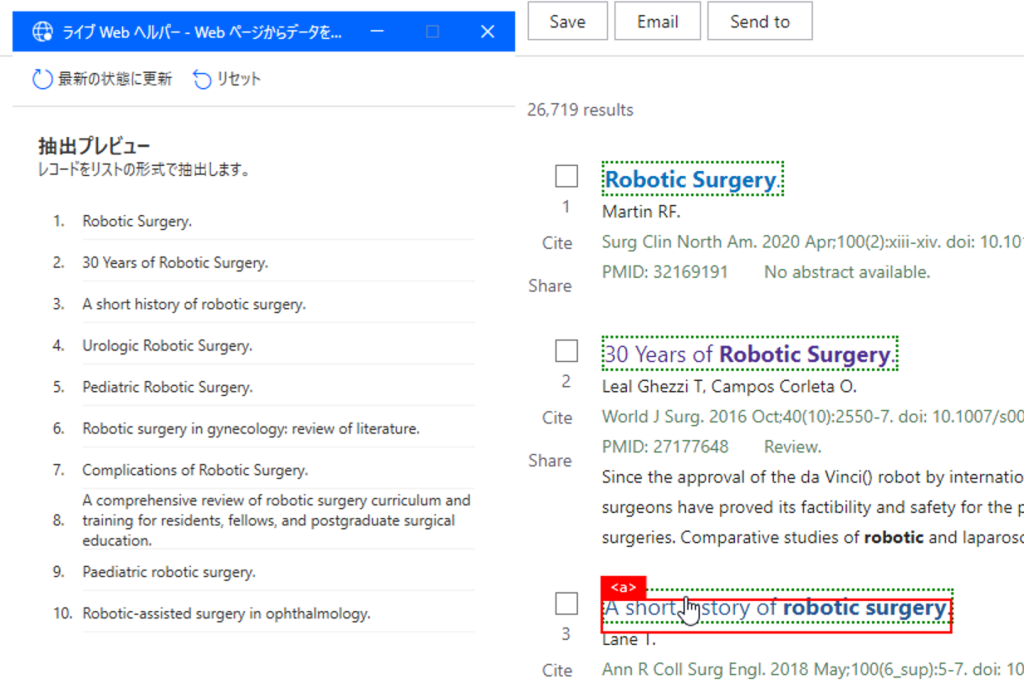
あとは、取得したい情報を、同じように赤い枠から登録していきます。抽出される情報は、プレビューに表示されますので、確認しながら進めて下さい。
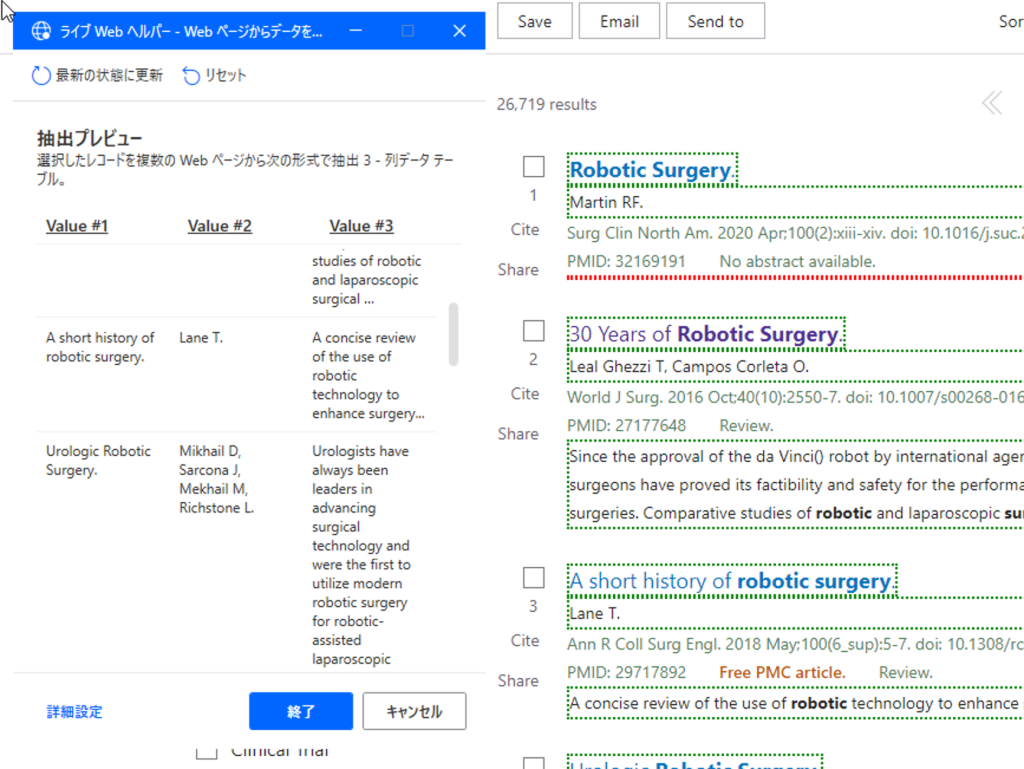
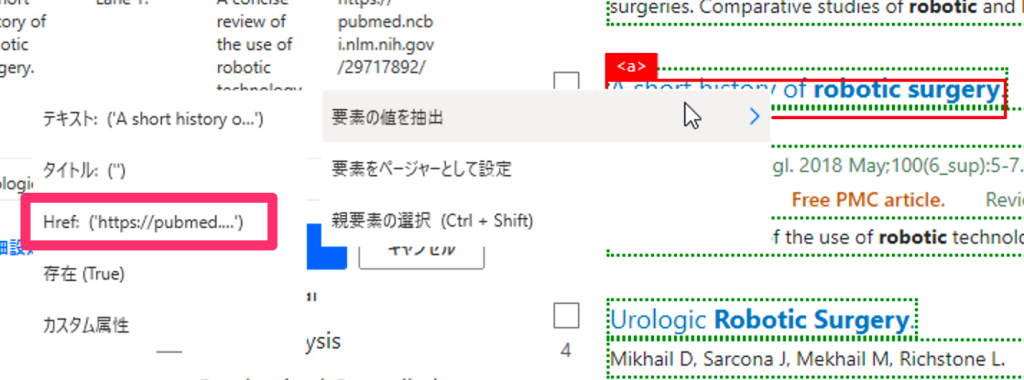
リンク先のURLを抽出する場合は、要素の値を抽出>Href:・・を選択します。
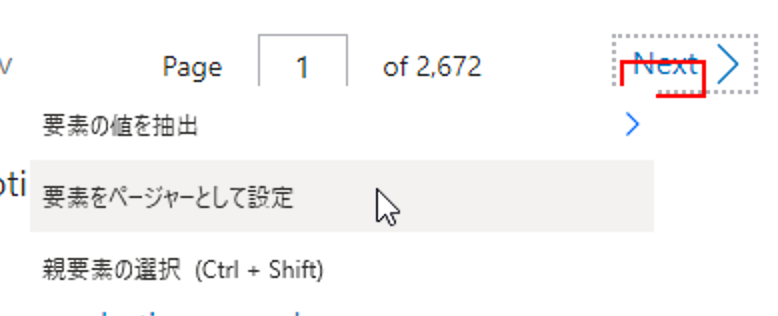
最後に、ページ下のNextから、「要素をページャーとして設定」を選択し、ライブWebヘルパーを「終了」して下さい。
Power Automateへ戻ると、「Webページからデータを抽出する」の画面が開いていますので、ここの「処理するWebページの最大数」に何ページ分を取得するかの値を入れて下さい。今回は10ページとします。
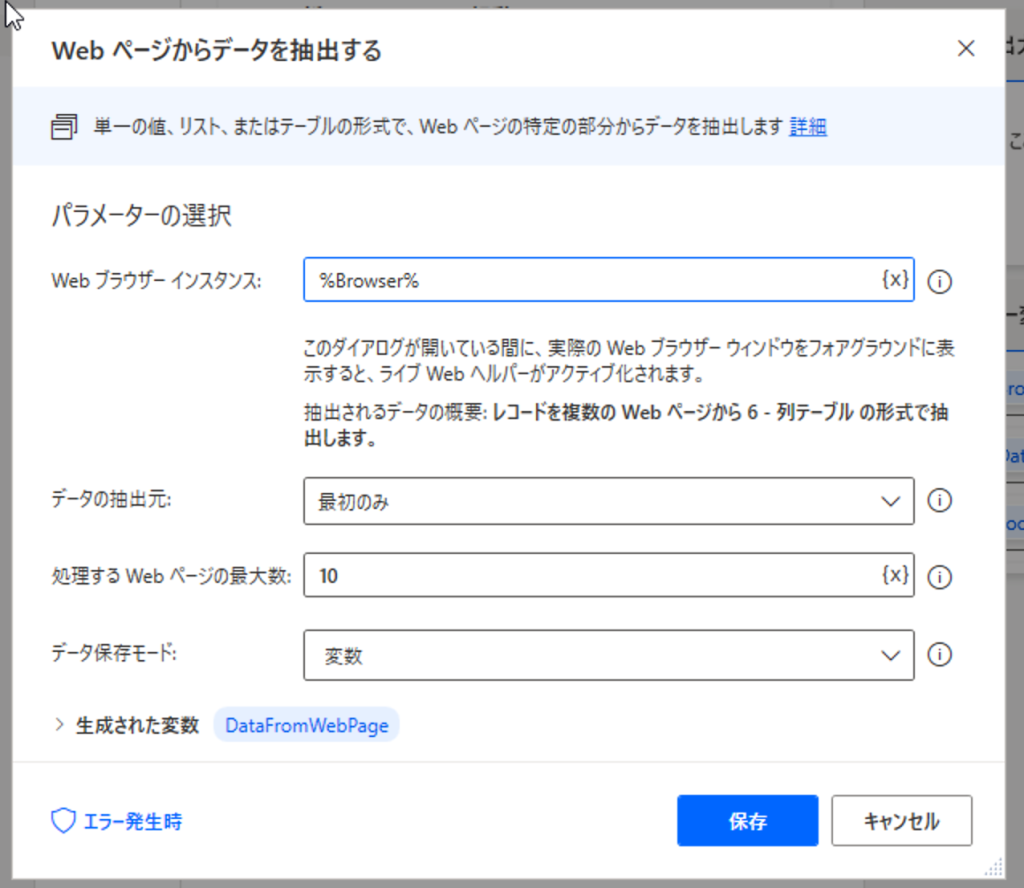
次に、アクション「CSVファイルに書き込みます」を「Webページからデータを抽出する」の下に追加します。図のように設定して下さい。「書き込む変数」には、「Webページからデータを抽出する」で生成した変数を指定します。「ファイルが存在する場合」は、「内容を追加する」を選択して下さい。これにより、Webから抽出したデータを、ひとつのCSVファイルに追加していくことができます。
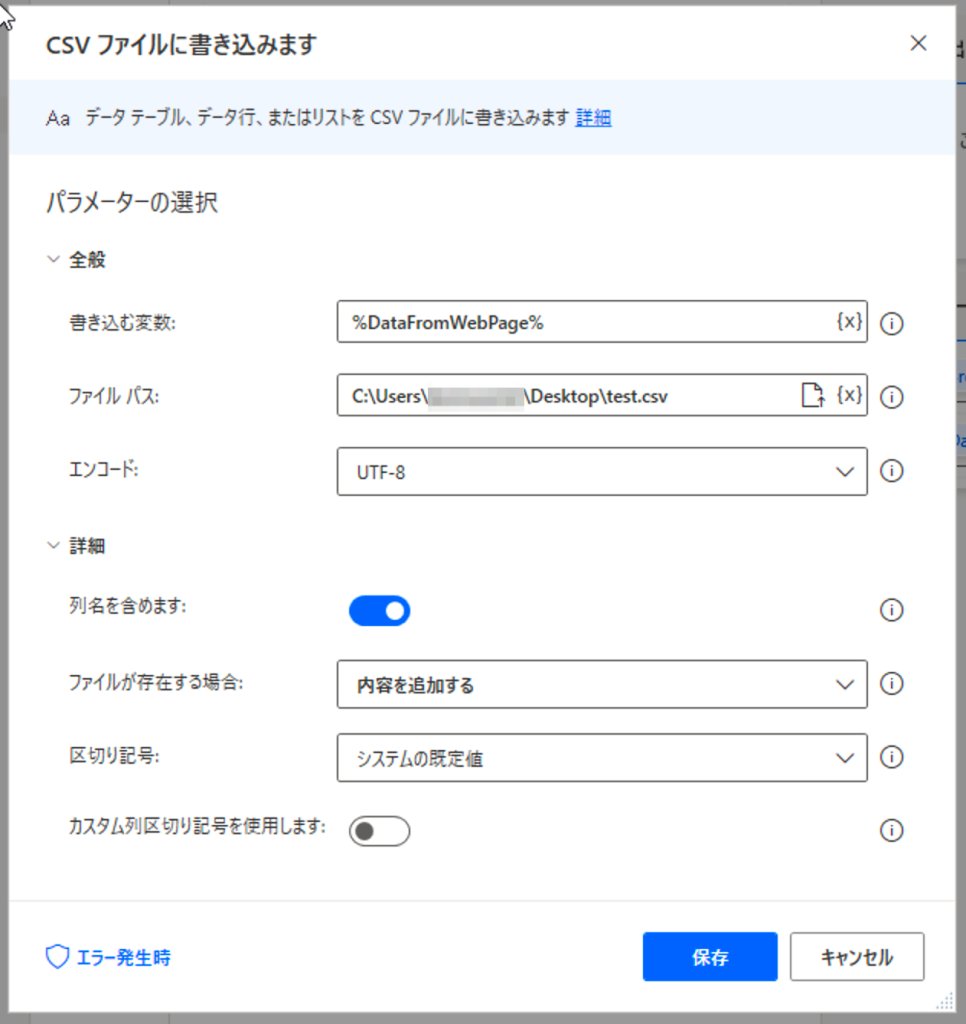
ここまでで、図のようになっているはずです。Chromeを起動し、PubMedを開いて検索をし、検索結果10ページ分を抽出し、CSVファイルに書き込んで、Nextを1度押しています。
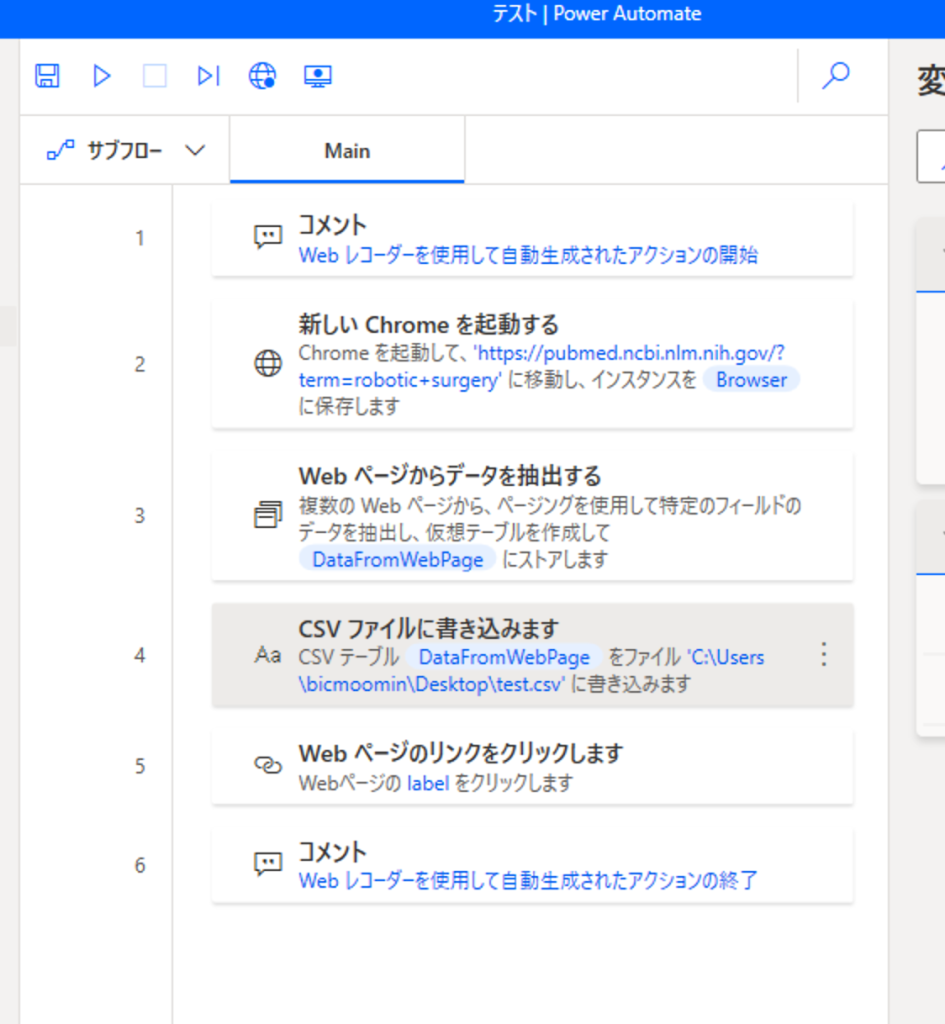
ここで、冒頭でもお伝えしましたように、クローリングは注意が必要です。ここがもう1つのポイントですが、連続して30ページ分を取得するのではなく、10ページごとにインターバルを置いて3回に分けて取得します。サーバーに負荷をかけないためです。ですので、アクション「Webページのリンクをクリックします」の下にWatiを追加し、60秒に設定しました。
そして、「Webページからデータを抽出する」からWaitまでの行を、Loop-Endで囲って繰り返し処理します。30ページ分なら3回です。100ページ(1000件)取得するなら、Loopを10回にします。
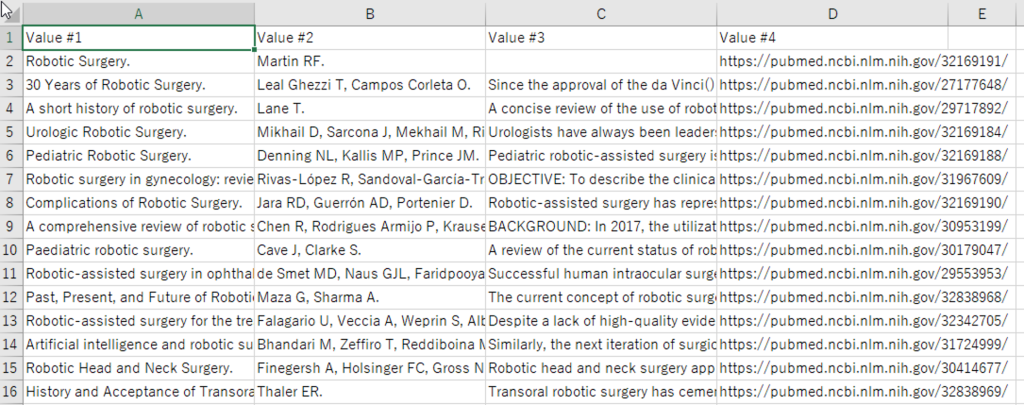
これでPubMedクローラーの完成です。上の実行ボタンを押して、テストしてみて下さい。もしエラーが出る場合は、ページ数やWait時間を調整して見て下さい。CSVを開くと図のようなデータが取得できているはずです。左から、タイトル、オーサー、アブストラクト、URLです。
もっとも大事なのは「解釈」
冒頭で述べました、Web情報を取得、可視化し、解釈する、この流れのうち、もっとも大事なのは「解釈」の部分です。可視化にも工夫は必要ですが、やはり、得られた結果をどう解釈し、戦略へつなげていくか。この部分にもっとも知恵を絞って、実効性のあるものにしなければ、そこまでの作業はすべて無駄だったということになります。
ですから、情報を取得する部分は、できるだけ手をかけずに、最小限の労力で済ます必要があります。今回はそこを重視し、これ以上ないほどに簡単な方法をご紹介しました。情報収集や可視化にばかり目が行っていませんか? 情報分析の目的、DXの目的は何なのか。いま一度、考えてみていただければと思います。
弊社のQuark Appsは、クローラー、RPA、テキスト分析、つながり解析、機械学習などの機能を、使い慣れたExcelから操作できるようにした情報分析ツールです。全国からのお問い合わせをお待ちしております。
