

社内に蓄積された膨大なデータは、新たな事業アイデアやブレイクスルーのヒントを秘めていながら、十分に活用されていないのが現状です。必要な情報へのアクセスが滞れば、価値創造の機会損失につながります。
この課題を解決する鍵が、大量データから新たな洞察を生み出す生成AIです。社内データへの適用で、必要な情報アクセスや知識の発見が容易になります。しかし、機密情報保護のため、クラウドサービスの利用は難しく、ローカル環境での構築が必須です。
そこで本記事では、社内データを安全に活用するローカル環境型生成AIシステムとして、有力なオープンソースツール「RAG搭載のDify」「RAGFlow」「ファイルクローラーのFess」の3つを比較検討していきましょう。
目次
オープンソースの比較まとめ:最適なツールを選ぶための視点
社内データを生成AIで活用する際、どのオープンソースツールを選択するかは、企業の既存システム、保有するデータ量、必要な機能によって大きく異なります。ここでは、今回比較対象としたDify、RAGFlow、Fessの3つのツールについて、主要な機能を比較し、それぞれのメリットとデメリットをまとめました。
| オープンソース | 自動取得更新 | チャンク化 | 段組み認識 | OCR | 参照精度 | メリット/デメリット |
|---|---|---|---|---|---|---|
| Dify | X | O | X | X | O | AI連携手軽/手動のナレッジ登録 |
| RAGFlow | X | O | O | O | X | OCRに強み/日本語対応が未熟 |
| Fess | O | X | X | X | O | ナレッジ登録の手間なし/AI連携弱い |
それぞれの現時点での推奨用途
上記の比較を踏まえ、現時点での各ツールの推奨用途は以下のようになります。
- ナレッジが少ない、または手動で厳選できる場合: Difyが最も手軽に導入でき、直感的な操作性でAIとの連携が可能です。特定の部門でのFAQシステムや小規模なナレッジベース構築に適しています。
- 論文や複雑なレイアウトのドキュメント、画像ベースのPDFなど、OCRによるテキスト抽出が必須の場合: RAGFlowがその強みを発揮します。ただし、日本語対応の成熟度や回答精度については、事前の詳細な検証が不可欠です。研究開発部門や特許調査部門などでの活用が考えられます。
- 社内に膨大な量の文書があり、自動的に収集・更新したい場合: Fessがその真価を発揮します。既存のファイルサーバーやドキュメント管理システムと連携し、自動で最新情報をAIに提供する基盤として非常に有効です。戦略部門や企画部門で、広範な社内情報を横断的に検索・活用したい場合に適しています。
Difyについて:手軽なAI連携とナレッジ管理
Difyは、生成AIアプリケーションの構築を容易にするプラットフォームです。RAG(Retrieval Augmented Generation)の機能も備えており、独自のナレッジベースをAIに参照させることで、より精度の高い回答を引き出すことができます。
Difyの主な特徴とメリット
- 直感的なワークフロー構築: Difyは、視覚的なインターフェースでAIアプリケーションのワークフローを設計できます。ナレッジの取り込みからモデルの選択、プロンプトの設定、出力形式の指定まで、一連の流れをドラッグ&ドロップで直感的に組み立てることが可能です。これにより、プログラミングの専門知識がなくても、比較的容易にAIシステムを構築できます。
- 柔軟なナレッジ設定: 登録するナレッジの「チャンク化(意味のある最小単位に分割すること)」やインデックス方法を細かく設定できます。例えば、ドキュメントの段落ごとにチャンク化したり、特定のキーワードに重み付けをしたりすることで、RAGの参照精度を高めることが可能です。
- 手軽な導入と利用: 登録するナレッジの量が少ない場合や、特定のドメインに特化したFAQシステムなどを構築する場合には、Difyは非常に手軽な選択肢となります。小規模な検証プロジェクトやPoC(概念実証)にも適しています。
- AI連携の容易さ: 複数のAIモデル(例:OpenAI、Anthropicなど)との連携が容易に設定できます。これにより、特定のタスクに最適なAIモデルを選択し、最大限の性能を引き出すことが可能です。
Difyの課題とデメリット
Difyは多くのメリットを持つ一方で、いくつかの課題も抱えています。
- ナレッジの手動登録: Difyにナレッジを登録する際は、基本的に手動でファイルをアップロードするか、API経由でデータを投入する必要があります。これは、頻繁に更新される大量のドキュメントを扱う場合や、既存のファイルサーバーから自動的にデータを収集したい場合には、大きな手間となります。
- OCR機能の不在: Difyには、画像ベースのPDFやスキャンされたドキュメントからテキストを抽出するOCR(光学文字認識)機能が標準では搭載されていません。そのため、テキスト情報が埋め込まれていないPDFファイル(例:スキャン画像として保存された論文や設計図)は、Dify単体では内容を認識できません。これは、紙媒体の資料が多いメーカーにとって大きな制約となる可能性があります。
- 段組み認識の限界: 論文や報告書など、複数の段組みで構成されたドキュメントのテキストを正しく認識できない場合があります。AIが参照する際に、文脈が途切れたり、誤った順序で情報が解釈されたりするリスクがあります。
これらの課題を踏まえると、Difyは、特定のテーマに絞ったナレッジベースを構築したい場合や、手動で厳選された情報をAIに学習させたい場合に非常に有効です。しかし、社内のあらゆるドキュメントを自動で取り込みたい、あるいはOCR機能が必須となる場合には、他のツールとの組み合わせや、追加の開発が必要になることを考慮する必要があります。
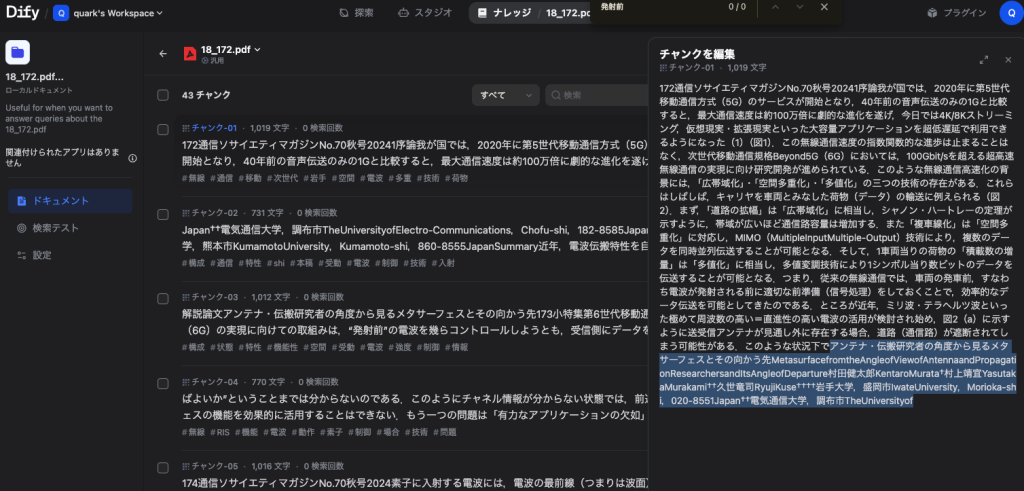
RAGFlowについて:高度なOCRと複雑なドキュメントへの対応
RAGFlowは、特に複雑なレイアウトのドキュメントや画像ベースのドキュメントからの情報抽出に強みを持つRAGシステムです。RAGFlowは、Difyと同様にRAGの機能を提供しますが、その最大の特徴は、高度なOCR機能と段組み認識能力にあります。
RAGFlowの主な特徴とメリット
- 高度な段組み認識: RAGFlowは、PDFなどのドキュメントにおける複数の段組み(例:学術論文の2段組)を正しく認識し、論理的な順序でテキストを抽出する能力に優れています。これにより、複雑なレイアウトのドキュメントでも、AIが文脈を正確に理解しやすくなります。
- 強力なOCR機能: 画像データやスキャンされたPDFからテキスト情報を抽出するOCR機能が非常に強力です。グラフデータや図表内のテキストも認識しようと試みるため、視覚情報に富んだ技術文書や研究論文の解析に特に有効です。画像ベースのPDFであっても、AIが内容を理解するためのテキストデータに変換できる点は、RAGFlowの大きな利点です。
- 参照元の明確化: AIの回答時に、参照したPDFの具体的なページ番号やセクションが表示されるため、ユーザーはAIの回答の根拠を容易に確認できます。これにより、情報の信頼性が高まり、ユーザーの納得感を得やすくなります。特に、正確性が求められる技術部門や研究部門での利用において、この機能は非常に重要です。
RAGFlowの課題とデメリット
RAGFlowはOCR機能において優れた能力を持つ一方で、いくつかの課題も存在します。
- 日本語対応の未熟さ: 筆者の検証では、画像PDFのテキスト情報が中国語で認識されるなど、日本語のOCR精度や全体的な日本語対応にまだ課題が見られます。これは、開発元が中国であることに起因する可能性があります。日本語のドキュメントが中心となる日本のメーカーにとっては、この点が導入の大きな障壁となる可能性があります。
- OCR認識精度の限界: グラフデータや画像内のテキストのOCR認識は試みられるものの、その精度は完璧ではありません。特に複雑な図や手書き文字、低品質な画像の場合、誤認識が発生する可能性が高く、完全に自動化するには追加の手動チェックが必要になることがあります。
- AI回答精度の課題: 今回の検証では、AIの回答精度が全体的に「あまりよろしくない印象」という結果でした。これは、リランクモデルの未適用、日本語の特殊性、あるいはモデルのチューニング不足など、様々な要因が考えられます。RAGのシステムは、参照元の情報がいかに正確であっても、その情報を活用するAIモデルの性能や、適切にチューニングされているかが回答精度に大きく影響します。本格導入前には、徹底的な検証とチューニングが不可欠です。
- 自動取得更新機能の不在: Difyと同様に、RAGFlowも基本的にナレッジの手動登録が必要です。大量のドキュメントを継続的に更新していく運用には、別途データ連携の仕組みを構築する必要があります。
RAGFlowは、学術論文や技術仕様書など、複雑なレイアウトや画像ベースの情報を多く含むドキュメントを扱う研究開発部門にとっては、非常に魅力的な選択肢となりえます。しかし、日本語での運用を主とする場合は、OCR精度やAI回答精度を詳細に検証し、必要に応じてカスタマイズや追加開発を行う覚悟が必要でしょう。

Fessについて:大量データと自動収集・更新の強み
Fessは、オープンソースの全文検索サーバーであり、特に大量の社内データを自動で収集・インデックス化し、高速な検索機能を提供する点で他の2つのツールとは一線を画します。Fess単体では直接的な生成AI機能は持ちませんが、AIと連携することで、社内データの自動活用システムの中核を担うことができます。
Fessの主な特徴とメリット
- ファイルクローラーによる自動収集・更新: Fessの最大の強みは、そのファイルクローラー機能です。社内ネットワーク上のファイルサーバー、Webサイト、データベースなど、多様な情報源から自動的にデータを収集し、検索対象としてインデックス化することができます。これにより、手動でのナレッジ登録の手間を大幅に削減し、常に最新の情報を検索可能に保つことができます。
- スケジューラ機能による自動更新: スケジューラに登録することで、指定した間隔で社内フォルダを巡回し、新規追加された文書や更新された文書を自動的にデータベースに反映させることが可能です。これは、日々更新される大量の技術資料や会議議事録などを扱う大手メーカーにとって、非常に大きなメリットとなります。
- 多様な文書形式への対応: PDF、Word、Excel、PowerPointなどの一般的なオフィス文書はもちろん、テキストファイル、HTMLファイルなど、幅広い文書形式に対応しています。これにより、社内に散在する様々な形式の情報を一元的に管理し、検索対象とすることができます。
- 全文検索エンジンの搭載: Fess自体が高速な全文検索エンジンを搭載しているため、AIが参照する前の段階で、ユーザーがキーワード検索によって目的の情報を素早く見つけ出すことが可能です。これは、AIの回答精度がまだ完璧ではない段階や、ユーザー自身が情報を探索したい場合に非常に役立ちます。
- AIとの連携による可能性: Fess単体ではAIの回答生成はできませんが、Fessで構築した検索インデックスを、DifyやRAGFlowなどのRAGシステムや、直接LLM(大規模言語モデル)のAPIと連携させることで、AIがFessの検索結果を基に回答を生成するシステムを構築できます。これにより、AIが常に最新かつ網羅的な社内情報を参照し、より精度の高い回答を生成することが可能になります。例えば、「AIからFessを参照するワークフロー」を構築すれば、ユーザーの質問に対してFessが関連文書を検索し、その検索結果をAIが要約・生成して回答するといった連携が考えられます。
Fessの課題とデメリット
Fessは非常に強力なデータ収集・検索基盤ですが、AI連携においてはいくつかの課題があります。
- チャンク化機能の不在: Fessは文書を「ファイル単位」でインデックス化するため、DifyやRAGFlowのように意味のある「チャンク」に分割する機能は標準では搭載していません。AIが回答を生成する際には、文書全体を読み込ませるよりも、関連性の高いチャンクを複数参照する方が効率的かつ精度が高まります。そのため、Fessの検索結果をAIに渡す前に、別途チャンク化の処理を行う必要があります。
- OCR機能の不在: Fessには標準ではOCR機能が搭載されていないため、画像ベースのPDFやスキャンされた文書からテキストを抽出することはできません。Fessでこれらの文書を検索可能にするには、事前にFessをカスタマイズし、OCR機能を有効にする必要があります。
- AI連携に一工夫が必要: Fessはあくまで検索エンジンであり、生成AIの回答生成機能は持ちません。そのため、AIと連携するには、FessのAPIを利用して検索結果を取得し、それをAIのプロンプトに組み込むといった追加の開発やワークフローの設計が必要です。DifyやRAGFlowのように、最初からRAG機能が組み込まれているツールと比較すると、AI連携の手間は増えます。
これらの点を踏まえると、Fessは、社内に散在する膨大な量の文書を自動で収集し、常に最新の状態に保ちたい企業に最適です。特に、戦略部門や企画部門で、広範な社内情報を横断的に検索し、その情報をAIに活用させたい場合に強力な基盤となります。しかし、AIの回答生成までをシームレスに行うには、FessをRAGシステムやLLMと連携させるための設計と開発が不可欠です。
今後の展望:社内データの真価を引き出すために
本記事では、社内データを生成AIで活用するためのオープンソースツールとして、Dify、RAGFlow、そしてFessの3つを比較検討しました。それぞれのツールには明確な強みと弱みがあり、貴社のニーズや保有するデータの特性に合わせて選択することが重要です。
- Difyは、手軽にAIアプリケーションを構築したい場合や、ナレッジの量が限定的で手動での管理が可能な場合に適しています。直感的な操作性で迅速なPoCや特定業務の効率化に貢献するでしょう。
- RAGFlowは、論文や技術資料など、複雑なレイアウトや画像情報を含むドキュメントの解析に強みを発揮します。研究開発部門での高度な情報抽出ニーズに応える可能性を秘めていますが、日本語対応や回答精度のさらなる検証が不可欠です。
- Fessは、社内に蓄積された膨大なデータを自動で収集・更新し、検索可能な状態に保つための強力な基盤となります。AIとの連携には一工夫必要ですが、常に最新かつ網羅的な情報をAIに提供できる点で、全社的な情報活用において計り知れない価値をもたらします。
社内データ活用の未来へ
これらのツールを単体で使うだけでなく、それぞれの強みを組み合わせるハイブリッドなアプローチも非常に有効です。例えば、Fessで社内データを自動収集し、その検索結果をDifyやRAGFlowのRAGシステムに渡し、AIが回答を生成するといった連携は、非常に強力なソリューションとなるでしょう。
社内データの活用は、単なる情報検索の効率化にとどまりません。生成AIとの組み合わせにより、これまで見過ごされてきたデータ間の関連性を発見したり、新たな知見やアイデアを創出したりといった、より高度な価値を生み出す可能性を秘めています。これは、新製品開発のスピードアップ、業務プロセスの最適化、競争戦略の策定など、企業のあらゆる活動にポジティブな影響をもたらすはずです。
次のステップへの問いかけ
貴社の戦略部門、企画部門、技術部門において、現在どのような情報活用に関する課題を抱えていらっしゃるでしょうか?そして、これらのオープンソースツールが、その課題解決にどのように貢献できるとお考えになりますか?
まずは、小規模なPoCから始めてみてはいかがでしょうか。眠れる社内データを呼び起こし、生成AIと共に新たな価値創造へと踏み出す一歩を踏み出してみませんか。
ひとこと
Difyでナレッジの自動更新ができると最強なのですが。調べてみると方法はありそうですが、ハードルが高そう。RAGFlowは文献の取り込みが正確で、当社のお客様向けに非常に期待したのですが、現時点では期待外れでした。同じようなモデルを使っても、AIからの回答がDifyより劣る印象。さらに、日本語入力にも問題があり、使っていてイライラしてしまいました(Difyも最初はそうでしたので、しばらく様子見)。そうなると、DifyとFessの連携が、今のところ実戦投入できそうな組み合わせです。何と言っても、Fessが自動で働いてくれるのがよいです。あとはDifyでワークフローを組んでしまえば、内製の社内AIシステムが出来上がってしまいます。
クォークでは、生成AIを活用した客観性のある戦略プランニング、特定分野に専門特化した生成AIの構築など、企業のR&Dを情報面でサポートする取り組みを継続しております。全国からのお問い合わせをお待ちしております。