
前回の記事では、生成AIの弱みである抽象的な質問に対し、タグクラウドで俯瞰してから具体的な切り口で深めていく、という内容でした。今回はその逆で、タグクラウドの情報を生成AIに認識させ、対象を大まかにとらえるという内容です。情報を収集したはいいものの、ざっくりどういうこと?を把握したい場合などに有効かと思います。ちょうど今月、ollamaのライブラリにllama3.2-vision(画像認識モデル)が登録されましたので、この11bモデルを使って試してみましょう。

llama3.2-visionについて
Llama 3.2 Vision は、Meta社が開発した大規模言語モデル(LLM)「Llama 3.2」の派生モデルで、画像とテキストの両方を理解できるマルチモーダルモデルです。
主な特徴は以下のとおりです。
画像とテキストの相互理解:
画像の内容を説明したり、画像から特定の情報(例えば、物体、シーン、感情など)を抽出し、テキストで表現することができます。テキストの説明に基づいて画像を生成したり、画像と関連する質問に答えることも可能です。
多様なタスクへの対応:
画像キャプション生成、視覚質問応答、画像検索、画像編集など、幅広いビジョンタスクに対応できます。
高い性能:
大量の画像とテキストデータを学習することで、画像認識や自然言語処理の両面で高い性能を発揮します。
ollamaのバージョンアップ
まず、llama3.2-visionを使うには、ollamaバージョン0.4以上が必要です。必要ならアップデートしてくだい。

アップデート方法は環境によって違いますが、当社ではDockerを使っていますので、古いollamaイメージを削除してから、再度docker compose upしました。
Dify設定のポイント
ポイントは2つです。
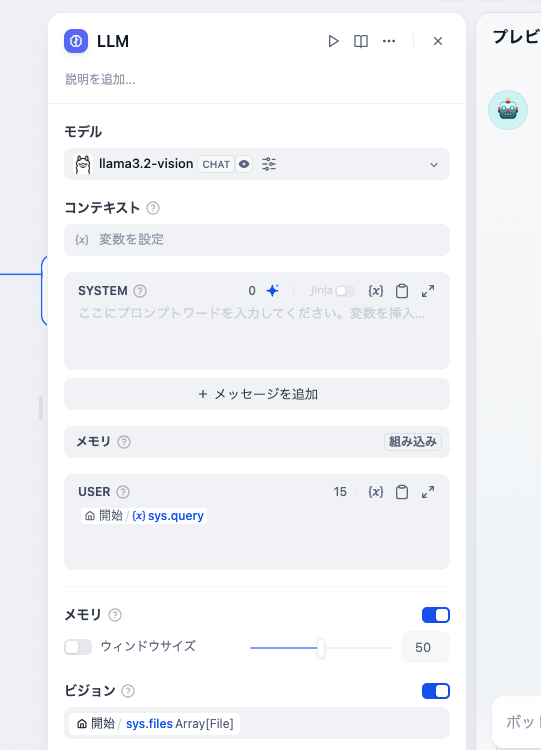
ひとつは、llama3.2-visionをDifyへ登録する際に、Vision supportをYesに設定してください。

もうひとつは、LLMノードのビジョン設定をオンにしてください。これで画像を受け付けるようになります。
画像認識のトライ
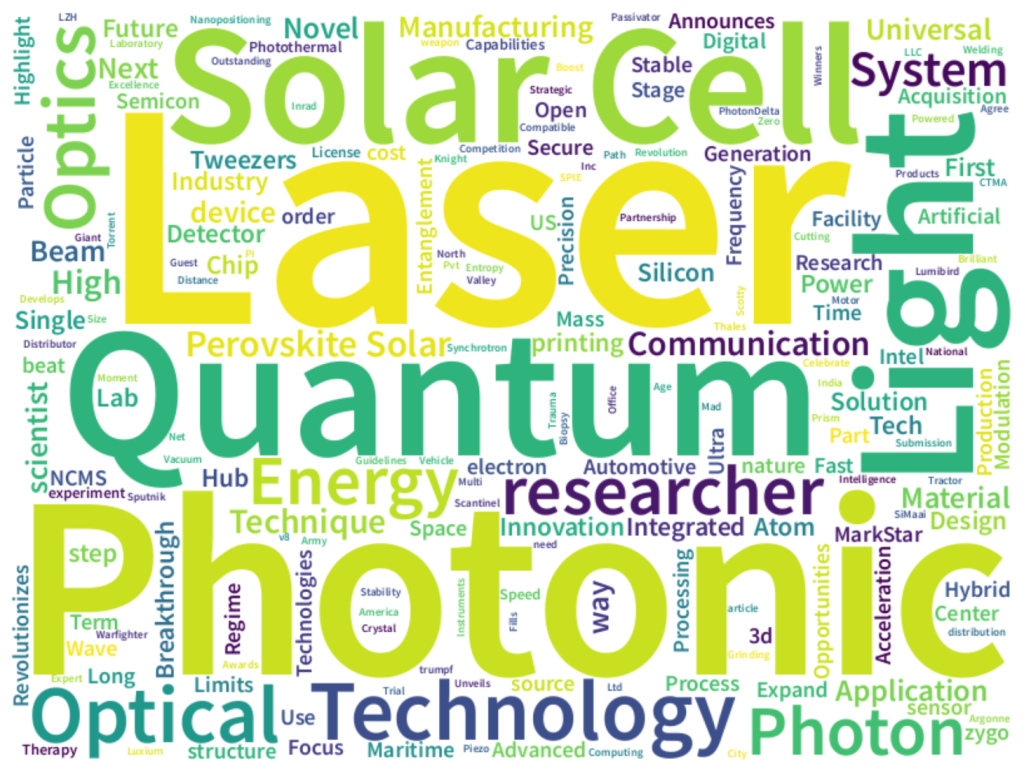
あるニュースサイトのRSSをもとに、100件程度のタイトル情報をワードクラウドにした画像を使ってみます(Quark AppsWebのWordCloudを使用)。
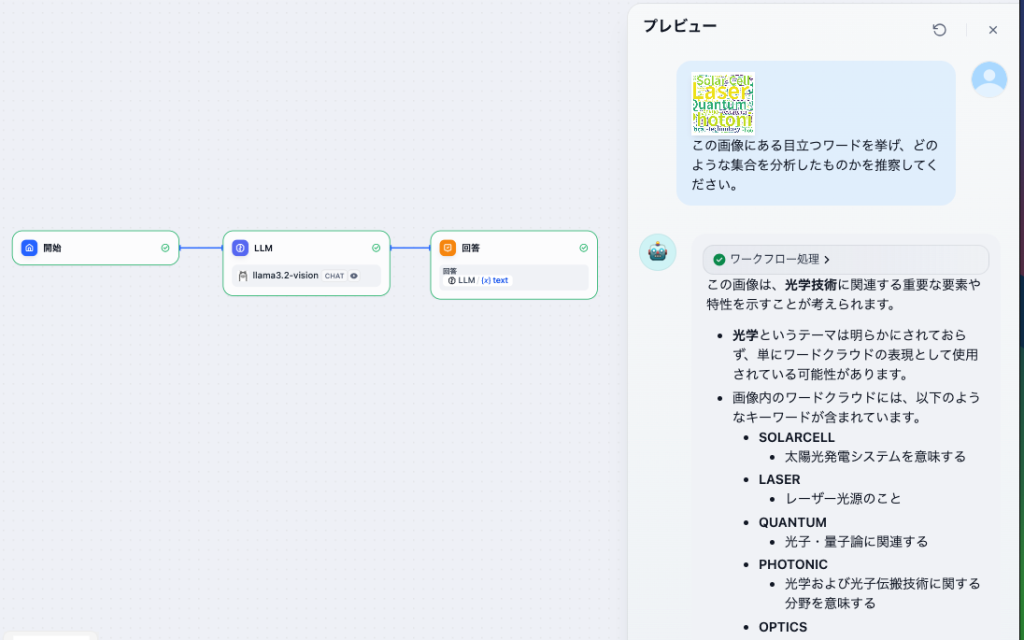
質問は、ただ認識させるだけでは生成AIの意味がないので、画像を分析し元の集合を推察させました。つまり、収集した情報が、ざっくりどのような傾向・動向になっているかを把握する意図です。その結果が以下です。目立つワードを認識し、光学関連技術を重要テーマとしてあげています。
まとめ
生成AIと画像認識を組み合わせることで、情報収集のプロセスを効率化し、より深く洞察を得ることができます。この手法は、様々な分野での情報分析に役立つと考えられます。今後の展望としては、より複雑な画像、多様なデータ形式への対応や、特定の分野への特化などが考えられます。