コンサルティングのプロジェクトなどで生成AIを使う場面が増えてきました。と言いますか、積極的に使っていこうという方針で進めています。ただ、実際に使ってみますと、そのままではほとんど役に立ちません。コンサルティングという性質上、完全ローカル環境で行っているため、モデルが小さいというのも原因の一つですが、一般論過ぎて話にならないのです。
プロンプト(質問文)を工夫するとか、モデルをいじるとか、いろいろ方法はあると思いますが、生成AIをあくまでツールとして使っている立場上、手間なく即効性のある方法が欲しいのです。例えば、2ヶ月以内に戦略までつくらないといけないのに、そんなに手間暇かけていられませんからね。
そこでRAGです。簡単に言うと追加学習です。テーマに関連する情報を収集し、これを生成AIに与えてもう少しマシな回答を得る仕組みです。モデルをファインチューニングする方法もありますが、まずは手軽なRAGからはじめます。ところがこのRAG、そう簡単ではありませんでした。精度を上げるには、これまた様々な方法があるわけです。そこで今回は、RAGの精度を上げるためにトライしたことの一部を紹介させていただきます。
Web情報の収集
今回は、企業動向を分析する目的で生成AIを活用する、といったシーンを想定して話を進めます。RAG投入用に、予め対象企業の情報を収集しておきます。今回はWebクローラーで自動収集していますが、手前味噌で恐縮ですが、当社のQuark AppsWeb(クローラー部分はオープンソースFess)を使っていきます。Quark AppsWebでは、収集した情報を様々な条件で抽出し、全文を含めcsv形式で一括ダウンロードできます。ここでは、対象企業のWeb情報を数十件ダウンロードします。
データの前処理
ダウンロードしたデータは、以下のような内容が含まれています。全文、タイトル、ダイジェスト、日付、URL、・・ただし、これらをそっくりそのままRAGに投入しても、思ったような結果が得られません。
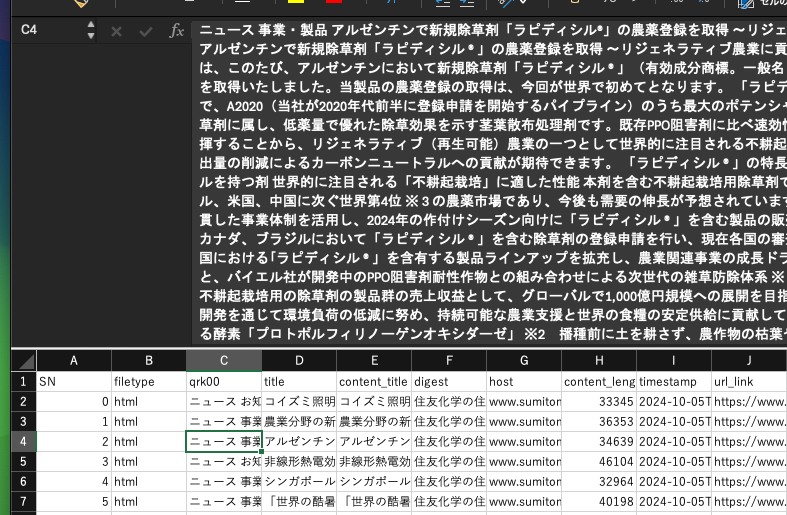
まず、全文を含んでいますので、文字数が多すぎるという問題があります。後述するナレッジの登録では、チャンクという塊に分割されるので登録自体はできるのですが、精度がイマイチです。1レコードが、複数チャンクに分割されてしまうからだと推測されます。
そこで、1レコード1チャンクで登録したいと考えました。そうすると、文字数を短くする必要が出てきます。そこで、digestの列を使うことを考えました。この列は、Webページのdescriptionから取得した要約部分と考えられます。しかしながらサイトによっては、以下のようにほとんど内容のないつくりになっている場合があります。
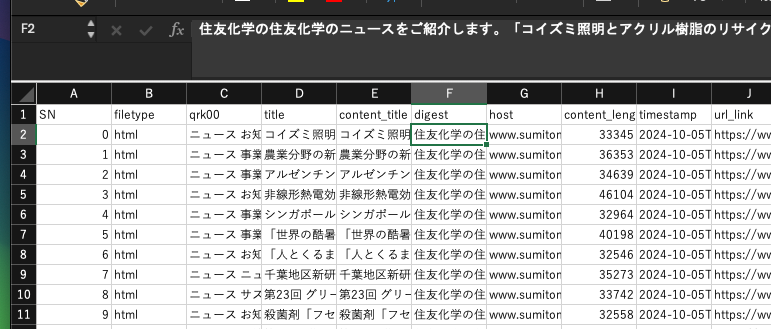
これでは全く役に立ちませんので、このような場合には、別の方法を考える必要があります。そこで、全文を参照し、新たに要約をつくる方法です。Quark AppsWebには、Summarizer(一括要約機能)がありますので、これを使って要約列を追加します。
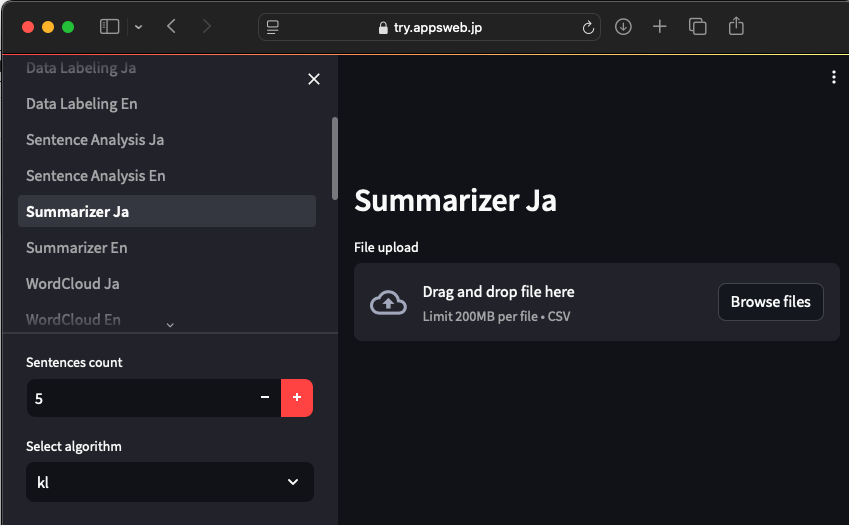
要約した結果は以下です。因みにQuark AppsWebは、自然言語処理エンジンとしてGINZAを使っています。どのくらいに要約するかは、サイドバーで設定できます。今回は5センテンスとしました。後述する、最大チャンク長を超えないようにします。これで、RAG投入の準備が整いました。

ナレッジの登録
Difyでは、追加学習用のデータは予め「ナレッジ」として登録しておきます。要約して1レコードの文字数を減らしたCSVを、Difyのナレッジへ登録します。
次に、チャンクの設定を行います。カスタムをクリックし、セグメント識別子に\nを入力します。これは、改行でチャンクを切るという意味です。最大チャンク長には、Dify最大値の1000(トークン)を入れていますが、前処理がされていれば、その前に改行で区切られます。1レコード1チャンクのような場合には、オーバーラップもあまり考えなくてよいと思います。
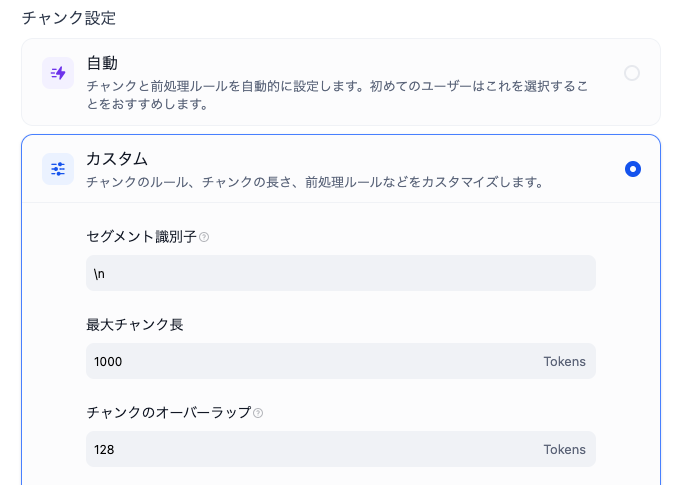
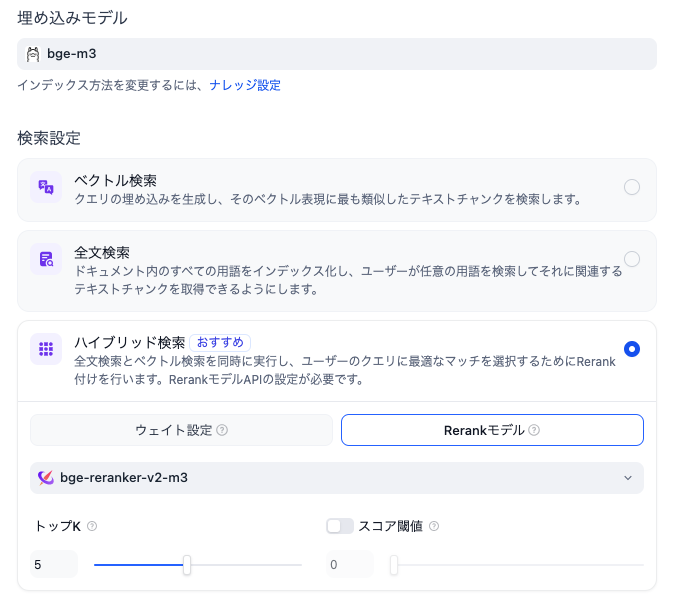
その他の設定も、簡単に解説します。埋め込みモデルは、bge-m3を使っています。当社の環境では、明らかにnomic-embed-txtやmxbai-embed-largeよりも精度が良かったからです。検索設定はハイブリッド検索を選択、リランクモデルはbge-reranker-v2-m3を使いました。これらはオープンソースのみで構成できますので、完全に無料です。
以上の設定で処理した結果が以下です。1レコード1チャンクで登録されています。チャンクの中身を確認すると、title、URL、Summaryがきれいに格納されています。ここまで長くなりましたので、このナレッジを使った効果については、別の機会にご報告いたします。